Research Projects

Nonverbal Interaction with Vision-Language Models
Current large language models and vision-language models rely mainly on natural language instructions, yet they do not fully make use of nonverbal information, which is an essential part of human communication. This study seeks to integrate physical expressions such as gaze, gestures, and facial expressions as input modalities for language models, aiming to create more intuitive and natural human–AI interactions. By developing core technologies that treat bodily actions themselves as input commands for AI, we open the way to communication styles beyond spoken language, while also improving the accessibility and inclusiveness of AI systems.
Large Language Models
Vision-Language Models
Human-Computer Interaction
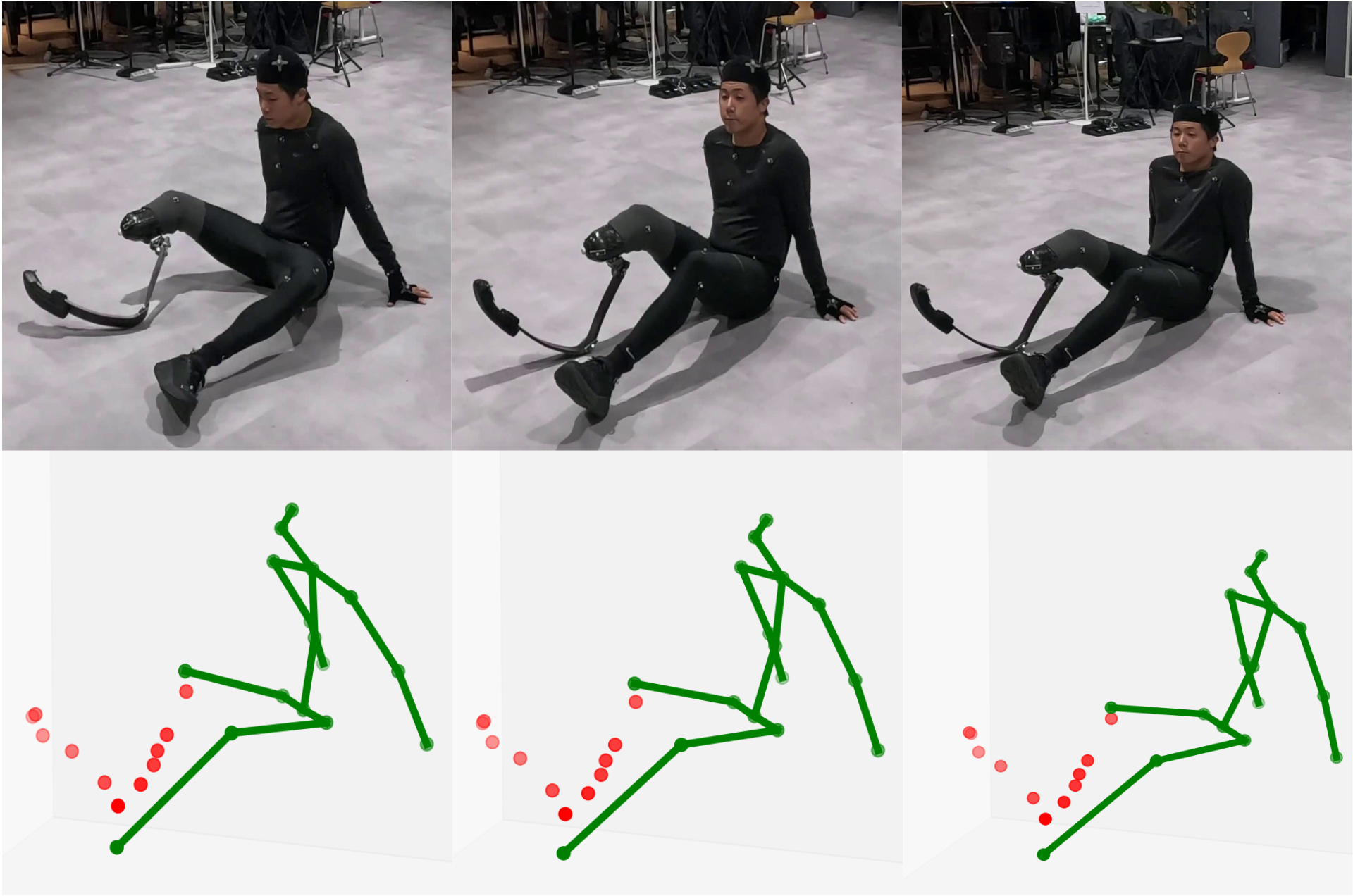
Inclusive 3D Pose Estimation for Prosthesis Users
Current pose estimation technologies are designed on the assumption of a “standard” body, which leads to the exclusion of people with diverse physical characteristics, including prosthesis users. This research addresses this problem directly by collecting and organizing 3D motion data from users of running-specific prostheses and building a benchmark to evaluate the limits of existing methods. By defining a new task that requires the simultaneous estimation of both natural body joints and prosthesis geometry, we are laying the research foundation needed to realize inclusive AI technologies.
Computer Vision
xDiversity

Embodied Interaction Design for Language Model Exploration
Despite the rapidly growing capabilities of large language models, unlocking their potential requires careful prompt design, which remains a significant barrier for non-expert users. This research explores physical and spatial interaction as an alternative entry point, allowing general users to experience language model inference in a more intuitive way. Users teach a device by pairing spoken words with demonstrated movements, and the device then responds autonomously to new utterances by generating corresponding actions. This makes the behavior of language models observable through the body. We evaluate this approach through studies conducted in public settings such as museums.
Large Language Models
Human-Computer Interaction
xDiversity

Generalizable Gaze Estimation through Large-Scale Pre-Training
Even when gaze estimation from camera images alone becomes possible, models trained on data collected in specific environments tend to perform poorly under unseen conditions. This research addresses the generalization problem from two directions: self-supervised pre-training on large-scale face image data, and multi-view estimation that uses the geometric relationships between multiple cameras. Through a pre-training design tailored to the geometric nature of gaze estimation as a regression task, we achieve robust estimation across unseen head poses and recording environments.
Computer Vision
Machine Learning

Participatory Training Data Collection through Gamification
High-quality large-scale data is essential for developing machine learning models, yet traditional data collection and evaluation methods tend to be repetitive and make it difficult to recruit a wide range of participants. This study builds a framework that combines data collection and evaluation with game elements, allowing participants to contribute while enjoying the experience. Through a cooperative two-player game for gaze estimation and a game designed to probe the limits of vision-language models, we collect diverse data while also fostering participants understanding of and interest in AI technologies.
Machine Learning
Participatory Design

Interactive Machine Learning for Non-Specialists
When designing systems based on machine learning, it is often not enough to simply consider the application of pre-trained models. In many cases, it is essential to provide a framework that allows users themselves to actively design their own recognition models. In our group, we address this challenge by developing systems that make machine learning accessible as a tool for general users. Through visualization methods, interface design for interactive machine learning environments, and analyses conducted in workshops, we pursue both system development and user evaluation, as well as public experiments.
Machine Learning
Human-Computer Interaction
xDiversity

Appearance-based Gaze Estimation
By recognizing where a person is looking within an environment, it becomes possible to estimate internal states related to attention and to provide flexible information according to the person’s focus. However, traditional gaze estimation methods have mainly relied on dedicated hardware, which limited their applications. We are developing a gaze estimation approach that requires only camera images as input, powered by large-scale training datasets and machine learning.
Computer Vision
Machine Learning